
AI Interview Best Practices for High-Volume Hiring
High-volume hiring breaks processes that work fine at normal scale. A rubric that produces decent results for 30 applicants starts generating noise at 300. A 25-minute interview session that gets 74% completion when you’re hiring 10 people might drop to 55% when you’re hiring 400 and candidates feel like a number in a queue. AI […]

High-volume hiring breaks processes that work fine at normal scale. A rubric that produces decent results for 30 applicants starts generating noise at 300. A 25-minute interview session that gets 74% completion when you’re hiring 10 people might drop to 55% when you’re hiring 400 and candidates feel like a number in a queue.
AI interview best practices for high-volume hiring aren’t just regular best practices turned up louder. The specific failure modes, the calibration requirements, and the candidate experience risks are all different when you’re processing hundreds of applicants for the same role. This guide covers what actually changes at scale — and what to do about it.
What Makes High-Volume AI Interviewing Different
At high volume, every configuration decision — rubric quality, invite timing, session length — gets amplified. Small errors in setup produce large errors in output when you’re processing hundreds of candidates simultaneously.
At normal hiring volumes, a slightly vague competency definition is a minor nuisance. At 300 applicants, that same vagueness produces inconsistent scores across a cohort large enough to influence real hiring decisions — and potentially trigger adverse impact flags.
The other key difference is candidate experience. When a company is hiring 400 warehouse associates, candidates know they’re one of hundreds. The AI interview process has to work harder to feel fair and respectful. Completion rates, invitation copy, and session length all matter more because the candidate’s trust threshold is lower going in.
Why It Matters
High-volume hiring is where AI interviews deliver the strongest ROI — but also where configuration errors cause the most damage, because they apply to every candidate at once.
The upside is real. A three-person recruiting team running 400 applications through a properly configured AI interview can produce a ranked shortlist in 48 hours. The same task done manually requires temporary recruiter capacity and 2–3 weeks.
The downside is equally real. A misconfigured rubric misranks 400 people. A confusing invite email tanks your completion rate and loses candidates who self-selected out for the wrong reason. At high volume, there’s no room for configuration debt.
Best Practices
The six practices below address the failure modes specific to high-volume contexts — the ones that don’t appear at 30 applicants but reliably surface at 200+.
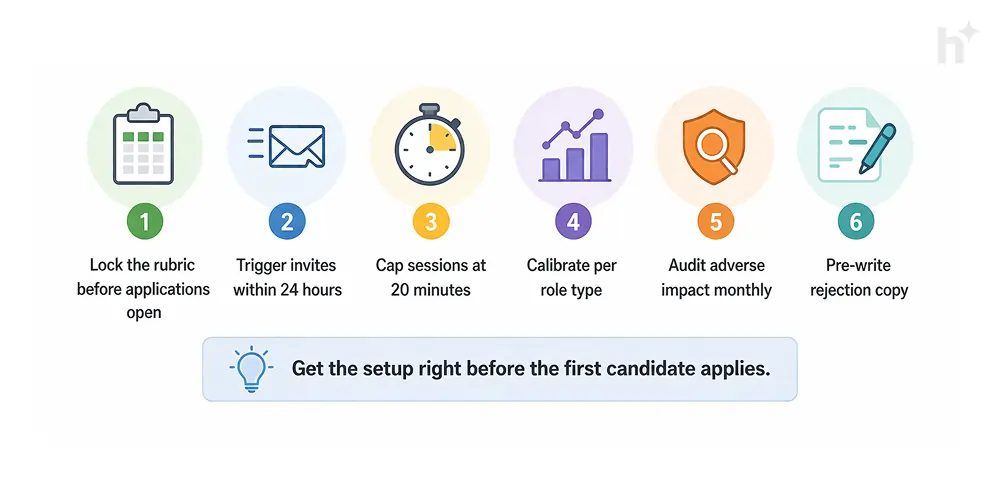
Lock the rubric before you open applications. At high volume there’s no time to calibrate mid-campaign. Define competencies, set observable behavioural criteria per score level, and freeze the rubric before the first invite goes out. Mid-campaign changes invalidate earlier scores and break your comparison pool.
- Before: Rubric built on day 3 of a 400-applicant campaign. First 80 candidates scored against a different standard. Rankings unreliable.
- After: Rubric signed off before job posting goes live. All 400 candidates scored against identical criteria. Shortlist defensible.
Set invite triggers, not invite batches. Weekly batch invitations are the single biggest driver of low completion rates in high-volume programmes. Set your ATS to trigger invitations automatically within 24 hours of application.
- Before: Weekly batch. Average 5-day delay. 58% completion rate.
- After: ATS-triggered within 24 hours. 76% completion rate on a 350-applicant campaign.
Cap sessions at 20 minutes and 5–6 questions. High-volume candidates apply to multiple positions simultaneously. A 30-minute session that works for a specialist role is too long for entry-level or volume roles.
- Before: 8 questions, 35 minutes. 52% completion. High drop-off after question 4.
- After: 5 questions, 18 minutes. 74% completion. Drop-off concentrated at question 1 (practice) only.
Run a calibration round for each new role type. At high volume you’ll often run the same platform across multiple role types simultaneously. Each needs its own calibration. A rubric validated for customer service will not transfer cleanly to warehouse operations without its own 10-response calibration round.
Audit for adverse impact monthly. In a standard programme, quarterly auditing is adequate. In high-volume, you accumulate enough data for statistically meaningful adverse impact analysis within weeks. Don’t wait for quarter-end to catch a bias signal that’s already affected hundreds of candidates.
Write the rejection communication before the campaign starts. At high volume, you’ll be rejecting hundreds of people. Write it once, write it well, and let the automation handle the rest. A specific, respectful automated rejection is a brand asset. A generic one — or silence — is a liability.
⚠️ Watch Out: The most common high-volume failure mode isn’t the technology — it’s launching a campaign before the rubric is locked. If your team is still debating competency definitions after invitations go out, your scores are already compromised.
| Condition | Recommended Action | Expected Outcome |
|---|---|---|
| 200+ applicants, single role | Async AI interview, 5 questions, 20-min cap | 70%+ completion, ranked shortlist in 48 hrs |
| Multiple role types simultaneously | Separate rubric and calibration per type | Consistent, role-specific scores |
| Completion rate below 60% | Audit invite timing and session length first | Typically recoverable with faster triggers |
| New role type added mid-programme | Run 10-response calibration before opening | Prevents mid-campaign miscalibration |
Common Challenges
High-volume AI interview programmes fail in predictable ways. The three most common are rubric drift mid-campaign, candidate experience erosion, and adverse impact blind spots.
Rubric Drift Mid-Campaign
Hiring managers sometimes request rubric changes mid-stream after seeing early shortlist results. This invalidates earlier scores and creates an inconsistent comparison pool. Treat the rubric as frozen once invitations go out. Log requested changes and apply them to the next campaign.
Candidate Experience Erosion at Scale
When candidates know they’re one of hundreds, impersonal automation reads as dismissive. Personalise the invitation email with the candidate’s name and the specific role. Add a line explaining why the process works the way it does. Small copy changes have a measurable effect on completion rates.
Adverse Impact Blind Spots
At 400 applicants, even a small scoring bias produces a statistically significant disparity in pass rates across demographic groups. Most teams don’t catch this until a quarter-end audit — by which point hundreds of potentially affected candidates have already been screened out.
⚠️ Watch Out: If your high-volume programme consistently produces shortlists that are demographically homogeneous compared to your applicant pool, the rubric is the first place to look. Adverse impact at scale doesn’t always indicate intentional bias — it often signals a competency definition that correlates with demographic characteristics rather than job performance.
Real-World Use Cases
The clearest ROI from high-volume AI interview best practices comes from campaigns where the alternative was agency spend or temporary recruiting headcount.
Logistics — 400 Associates, 6 Weeks. A UK 3PL operator running peak-season hiring for 400 warehouse associates implemented a 5-question, 18-minute AI interview with ATS-triggered invitations within 12 hours of application. Completion rate: 73%. All 400 roles filled within the 6-week window by a team of three, with no agency support — saving approximately £42,000 compared to the prior year’s agency model.
Retail — 600 Store Associates, 8 Weeks. A national retailer ran AI interviews across 80 locations simultaneously using a single calibrated rubric with location-specific threshold adjustments. Time-to-shortlist averaged 3.1 days across all locations. The prior year’s manual process averaged 14 days per location.
🏆 Best Result: The logistics case: 400 roles, 6-week window, three-person team, zero agency spend. That’s the compounding effect of getting the basics right — fast invitations, short sessions, locked rubric — before the campaign opens.
Metrics to Track
In high-volume programmes, completion rate and adverse impact ratio are more operationally critical than in standard programmes — because small deviations compound across large candidate pools.
| Metric | What It Measures | Target for High-Volume |
|---|---|---|
| Completion Rate | Candidate engagement with the process | 70%+ (below 60% needs immediate diagnosis) |
| Time-to-Shortlist | Core efficiency gain | < 3 business days for 200+ applicant roles |
| Adverse Impact Ratio | Bias risk across demographic groups | ≥ 0.80 — audit monthly |
| AI-to-Human Agreement | Rubric calibration accuracy | 75%+ match on calibration review |
| Drop-off by Question | Where candidates abandon the session | Flag any question losing 15%+ of candidates |
Drop-off by question is specific to high-volume contexts. When you have 300+ responses, you have enough data to identify exactly which question is causing abandonment. A question losing 20% of candidates is either too long, too ambiguous, or poorly sequenced. Fix it before the next campaign.
Frequently Asked Questions
How many questions should a high-volume AI interview include?
Five to six questions, with a hard cap of 20 minutes total. High-volume candidates are typically applying to multiple roles simultaneously and have less patience for long processes. Every question should tie directly to a scored competency — no warm-up questions that don’t contribute to the ranking.
How quickly should invitations go out in a high-volume campaign?
Within 24 hours of application, ideally within 12. Completion rates drop measurably when invitation delay exceeds 48 hours. Speed of invitation is also a competitive signal — candidates applying to multiple similar roles simultaneously will engage first with whoever reaches them first.
How often should I audit for adverse impact in a high-volume programme?
Monthly. Standard programmes can run quarterly audits because they don’t accumulate enough data for statistically meaningful analysis more frequently. High-volume programmes accumulate that data in weeks. Monthly audits catch bias signals before they affect large numbers of candidates.
Can the same rubric run across multiple high-volume roles?
Only if the roles share the same core competencies at the same performance level. Even then, each role type needs its own calibration round. A rubric validated for customer service should not apply to warehouse operations without separate calibration — the observable behaviours indicating competence are different.
What’s the main reason high-volume AI interview programmes underperform?
Rubric misconfiguration, almost always. The second most common reason is late or poorly written invitations suppressing completion rates. Technology failure is a distant third. The highest-leverage improvements are always in setup and communication, not the platform itself.
Conclusion
High-volume AI interviewing works when the fundamentals are locked in before the campaign opens: a calibrated rubric, fast invitation triggers, sessions short enough to respect candidate time, and an audit cadence that catches adverse impact signals early.
None of that is complex. But all of it requires doing the work before the first application arrives — not after the completion rate data comes in. Get the setup right and AI interviews at high volume are one of the highest-ROI tools in a recruitment team’s stack.
hiremore AI is built for exactly this context — high-volume screening with the scoring transparency and calibration tools that make the shortlist trustworthy. See how it handles your next peak hiring campaign.

